벌써 4번째 기술블로그~
<목차>
1. 깔끔한 데이터 만들기 1
2. 깔끔한 데이터 만들기 2
3. apply() with 람다 함수
1. 깔끔한 데이터 만들기 1
책에서 제공하는 pew.csv 파일을 이용해서 실습해볼꺼니까..
import pandas as pd
pew = pd.read_csv('../data/pew.csv')판다스에 파일을 먼저 불러와준 후에...
 |
데이터셋을 살펴보면, 일부 열 이름이 변수가 아닌 값을 나타낸다는 것을 알 수 있다. religion을 제외한 모든 열은 소득 범위를 나타내고, 각 소득 범위에 해당하는 사람의 수를 값으로 설정했다고 볼 수 있다. => 변수 '소득'을 여러 범위로 나눠서 여러 열로 분산시켰다는 것이다. |
변수 하나를 여러 개의 열로 표현한 데이터를 'wide data'라 하고, 한 개의 열로 표현한 데이터를 'long data'라 하자.
wide data를 long data로 만들려면 프레임을 변환하는 unpivot, 피벗 되돌리기 작업이 필요하다.
<melt() 매서드>
판다스의 데이터프레임에는 깔끔한 데이터 형식으로 변환하는 melt() 매서드가 존재한다.
4가지 매개변수를 지정해야 하는데...
| id_vars | 그대로 유지할 변수를 나타내는 컨테이너(리스트, 튜플, ndarray) |
| value_vars | unpivot 할 열을 나타냄. 기본적으로 id_vars로 지정하지 않은 모든 열. |
| var_name | unpivot 한 열의 이름을 값으로 하는 새 열의 이름을 나타냄. 기본값은 'variable' |
| value_name | var_name 열의 값을 나타내는 새로운 열의 이름 문자열. 기본값은 'value' |
흠.... 이렇게 설명으로만 쓰니까 너무 어려워보임....
 |
 |
id_vars="religion" / religion 열만 남긴다.
var_name="income" / unpivot할 열의 이름을 설정
value_name="count" / unpivot할 열들에 원래 있던 값들을 나타내는 이름
머 이정도...?
위에서는 하나의 열만 유지했었으니까 이번엔 2개 이상의 열을 남겨보는 걸 해볼거에요~
이번엔 다른 데이터셋 billboard.csv를 불러오겠어.
 |
데이터셋을 살펴보면,, year(연도), track(곡), time(재생시간), date.entered(발매일), 각 주들이 있다... |
생각을 해보자. 어떤 열을 unpivot해야 데이터가 깔끔해질까???
바로 wk1, wk2 ...... 얘네들이다.
 |
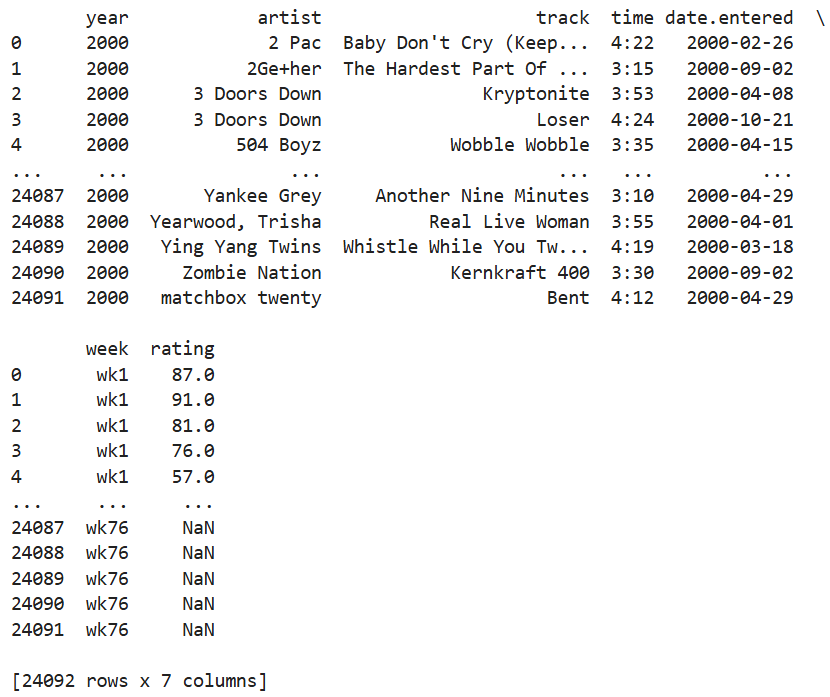 |
이런식으로!!!! 하면 좀 깔끔한 데이터가 만들어진 거 같기도////?
2. 깔끔한 데이터 만들기 2
내용이 생각보다 많아서 목차를 나눠보앗다..
이번엔 에볼라 데이터셋을 활용해볼 차례~!
ebola = pd.read_csv('../data/country_timeseries.csv') 데이터셋 열 이름 확인 |
 |
|
 'Date'랑 'Day'만 제외하고 정리 |
 |
|
| variable을 보면, Case_국가, Deaths_국가 형태임. 밑줄 앞은 사례, 뒤는 국가이므로 밑줄 기준으로 분할하면 좋을 듯...? variable_split = ebola_long.variable.str.split('_') 분할했으면 분할한 값을 새로운 열로 할당해야겠지요?? 리스트 각 값에 접근할려면 get() 이용해야됨! status_values = variable_split.str.get(0) country_values = variable_split.str.get(1) 이런식으로...! |
||
 원하는 시리즈 완성했으니까 데이터프레임에 추가하고 출력해주면 끝!! |
 |
|
3. apply() with 람다 함수
apply()매서드로 많은 걸 할 수 있지만, 그 중에 람다 함수를 사용하는 코드를 소개해 보겠다.
왜냐?
교수님이 내주신 과제에 lambda써야되는게 있었는데, 내가 필요성을 못 느꼈어서... 이번에 제대로 느껴보고자...ㅎ...
일단 예시를 먼저 살펴보는게 이해가 빠를 것이다.
간단한 데이터프레임과 함수를 만들어보면
df = pd.DataFrame({'a': [10, 20, 30],
'b': [20, 30, 40]})
def my_sq(x):
return x ** 2
데이터프레임과 함수를 사용해보면
 |
 |
왼쪽 코드처럼 만든 함수를 사용할 수도 있지만, 제곱같이 간단한 함수는 lambda를 쓰면 간단하게 정리할 수 있다.
따로 정의 안해도 되도록 하는 친구가 람다 함수이다.
오늘은 여기까지. 안녕!